Your website gained’t rank if search engine bots can’t crawl it. And hidden doorways that don’t impression human guests can lock bots out.
Analyzing crawls will reveal and unlock the hidden doorways. Then bots can enter your website, entry your info, and index it in order that it may well seem in search outcomes.
Use the next eight steps to make sure search bots can entry your complete ecommerce website.
Website Blockers
Can bots enter the location?
First, verify to see if it’s worthwhile to unlock the entrance door. The arcane robots.txt textual content file has the facility to inform bots to not crawl something in your website. Robots.txt is all the time named the identical and situated in the identical place in your area: https://www.instance.com/robots.txt.
Ensure robots.txt doesn’t “disallow,” or block, search engine bots out of your website.
Name your developer staff instantly in case your robots.txt file consists of the instructions under.
Consumer-agent: *
Disallow: /Rendering
Can bots render your website?
As soon as they get by way of the door, bots want to seek out content material. However they can’t instantly render some code — akin to superior JavaScript frameworks (Angular, React, others). Consequently, Google gained’t have the ability to render the pages to index the content material and crawl their hyperlinks till weeks or months after crawling them. And different search engines might not have the ability to index the pages in any respect.
Use the URL inspection software in Google Search Console and Google’s separate cellular-pleasant check to verify whether or not Google can render a web page, or not.

Use Search Console’s URL inspection device to see how Google renders a web page. This instance is Sensible Ecommerce’s home page. Click on picture to enlarge.
Websites utilizing Angular, React, or comparable JavaScript frameworks ought to pre-render their content material for consumer-brokers that may’t in any other case show it. “Consumer-agent” is a technical time period for something that requests an internet web page, resembling a browser, bot, or display reader.
Cloaking
Are you serving the identical content material to all consumer brokers, together with search engine bots?
Cloaking is an previous spam tactic to unfairly affect the search outcomes by displaying one model of a web page to people and a unique, key phrase-crammed web page to look engine bots. All main search engines can detect cloaking and can penalize it with decreased or no rankings.
Typically cloaking happens unintentionally — what seems to be cloaking is simply two content material techniques in your website being out of sync.
Google’s URL inspection software and cellular-pleasant check may also assist with this. It’s a very good begin if each render a web page the identical as an ordinary browser.
However you possibly can’t see the whole web page or navigate it in these instruments. A consumer-agent spoofer akin to Google’s Consumer-Agent Switcher for Chrome can verify for positive. It allows your browser to imitate any consumer agent — i.e., Googlebot smartphone. Consumer-agent spoofers in any main browser will work, in my expertise.
Nevertheless, it sometimes requires manually including Googlebot, Bingbot, and some other search engine consumer-agent. Go to the choices or settings menu on your spoofer (a browser extension, sometimes) and add these 4.
- Googlebot smartphone:
Mozilla/5.zero (Linux; Android 6.zero.1; Nexus 5X Construct/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/forty one.zero.2272.ninety six Cellular Safari/537.36 (suitable; Googlebot/2.1; +http://www.google.com/bot.html) - Googlebot desktop:
Mozilla/5.zero (suitable; Googlebot/2.1; +http://www.google.com/bot.html) - Bingbot cellular:
Mozilla/5.zero (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.fifty one.1 (KHTML, like Gecko) Model/7.zero Cellular/11A465 Safari/9537.fifty three (suitable; bingbot/2.zero; +http://www.bing.com/bingbot.htm) - Bingbot desktop:
Mozilla/5.zero (suitable; bingbot/2.zero; +http://www.bing.com/bingbot.htm)
Now you possibly can flip your means to spoof search engine bots on and off out of your browser. Load a minimum of your home page and make sure that it seems the identical whenever you’re spoofing Googlebot and Bingbot because it does once you go to the location usually in your browser.
Crawl Price
Do Google and Bing crawl the location persistently over time?
Google Search Console and Bing Webmaster Instruments every present the instruments to diagnose your crawl fee. Search for a constant development line of crawling. In case you see any spikes or valleys within the knowledge, particularly if it units a brand new plateau on your crawl fee, examine into what might have occurred on that day.
Inner Hyperlink Crawlability
Are hyperlinks in your website coded with anchor tags utilizing hrefs and anchor textual content?
Google has said that it acknowledges solely hyperlinks coded with anchor tags and hrefs and that the hyperlinks ought to have anchor textual content, too. Two examples are the “Might be crawled” hyperlinks, under.
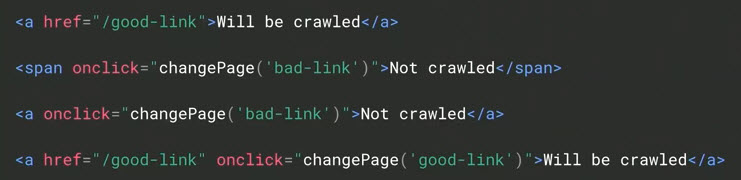
This hypothetical markup highlights the distinction to Google between crawlable hyperlinks and uncrawlable — “Shall be crawled” vs. “Not crawled.” Supply: Google.
Chrome consists of useful, preinstalled developer instruments for hyperlink crawlability. Proper-click on any hyperlink and choose “examine” to see the code that makes that hyperlink seen.

In Chrome, proper-click on any hyperlink and choose “Examine” to see the code. Click on picture to enlarge.
Bot Exclusion
Are bots allowed to entry the content material they should and excluded from seeing content material that has no worth to natural search?
Step one above was checking the robots.txt file to be sure that bots can enter your website’s entrance door. This step is about excluding them from low-worth content material. Examples embrace your buying cart, inner search pages, printer-pleasant pages, refer-a-good friend, and need lists.
Search engine crawlers will solely spend a restricted period of time in your website. That is referred to as crawl fairness. Ensure that your crawl fairness is spent on an important content material.
Load the robots.txt file in your area (once more, one thing like https://www.instance.com/robots.txt) and analyze it to make it possible for bots can and can’t entry the correct pages in your website.
The definitive useful resource at Robotstxt.org accommodates info on the precise syntax. Check potential modifications with Search Console’s robots.txt testing device.
URL Construction
Are your URLs correctly structured for crawling?
Regardless of the hype about optimizing URLs, efficient crawling requires solely that URL characters meet 4 circumstances: lowercase, alpha-numeric, hyphen separated, and no hashtags.
Key phrase-targeted URLs don’t influence crawling, however they ship small alerts to search engines of a web page’s relevance. Thus key phrases in URLs are useful, as nicely. I’ve addressed optimizing URLs, at “SEO: Creating the Perfect URL, or Not.”
Utilizing a crawler is one approach to analyze the URLs in your website in bulk. For websites beneath 500 pages, a free trial of Screaming Frog’s will do the trick. For bigger websites, you’ll have to buy the complete model. Options to Screaming Frog embrace DeepCrawl, Hyperlink Sleuth, SEMrush, and Ahrefs, to call a number of.
You might additionally obtain a report out of your net analytics package deal that exhibits all the URLs visited within the final yr. For instance, in Google Analytics use the Conduct > Website Content material > All Pages report. Export all of it (a most of 5,000 URLs at a time).
As soon as accomplished, type the report of URLs alphabetically. Search for patterns of uppercase URLs, particular characters, and hashtags.
XML Sitemap
Lastly, does your XML sitemap mirror solely legitimate URLs?
The XML sitemap’s sole objective is facilitating crawls — to assist serps uncover and entry particular person URLs. XML sitemaps are a great way to make sure that search engines like google and yahoo find out about all your class, product, and content material pages. However sitemaps don’t assure indexation.
You first have to seek out your XML sitemap to see which URLs are in it. A typical URL is https://www.instance.com/sitemap.xml or https://www.instance.com/sitemapindex.xml. It may be named something, although.
The robots.txt file ought to hyperlink to the XML sitemap or its index to assist search engine crawlers discover it. Head again to your robots.txt file and search for one thing like this:
Sitemap: https://www.instance.com/sitemap.xmlIf it’s not there, add it.
Additionally, add the sitemap URL to Google Search Console and Bing Webmaster Instruments.
Your XML sitemap ought to include no less than the identical variety of URLs as SKUs and classes, content material, and site pages. If not, it could possibly be lacking key URLs, corresponding to product pages.
Additionally, make sure that the URLs within the XML sitemap are present. I’ve seen sitemaps with URLs from previous variations of web sites, discontinued merchandise, and closed places. These must be eliminated. Something lacking out of your XML sitemap is liable to not being found and crawled by serps.
See the subsequent installment: “6-step web optimization Indexation Audit for Ecommerce.”