Typically web sites have search-engine-optimization issues that Google Search Console, Google Analytics, and off-the shelf search engine marketing instruments can’t find. When this happens, I typically depend on an previous-faculty technique: net server logs.
What Are Net Server Logs?
You might assume that Google Analytics or comparable analytics platforms report each go to to your website. Nevertheless, analytics platforms don’t report most robotic visits, together with search engine bots.
Net server logs, nevertheless, report each go to to your website, whether or not from people or robots. Consider net server logs as automated journals of all of the exercise in your website. They sometimes embrace the originating IP handle of the customer, the browser-consumer brokers, the pages requested, and the web page the place the customer got here from.
The primary problem with server logs is that info is in a uncooked format. It’s essential to take additional steps to research the info.
For instance, right here’s what an Apache mixed log format appears like.
sixty six.249.sixty four.34 - frank [05/Apr/2017:thirteen:fifty five:36 -0700] "GET /product-123 HTTP/1.1" 200 2326 "http://www.webstore.com/house.html" "Mozilla/5.zero (suitable; Googlebot/2.1; +http://www.google.com/bot.html)"
I’ve underlined the important thing elements of the log: the IP handle of the customer, the time of the go to, the web page visited, the referring web page, and the customer or bot. You should use the IP tackle to confirm Googlebot visits.
three Examples of Utilizing Server Logs
Listed here are three current examples the place I used net server logs to get to the basis of web optimization issues.
The primary instance comes from my work with a multinational company. Google Search Console > Crawl > Sitemaps reported greater than one hundred,000 pages within the XML sitemaps, however Google listed lower than 20,000 of them. Nevertheless, Search Console > Google Index > Index Standing reported greater than 70,000 pages listed.
How is that this attainable?
Google can index many duplicate or stale pages and miss the “actual” pages of a website. The arduous half is figuring out which duplicate pages are listed and which actual pages aren’t.
Sadly, Google Search Console doesn’t present an inventory of listed URLs or inform you which pages out of your XML sitemaps are not listed. To deal with the issue, we would have liked the reply to each of these questions.
On this case, I acquired server logs masking the top of January to the start of March. After analyzing them, we discovered that lower than 9 % of the pages within the XML sitemap had been crawled by Google throughout that interval.
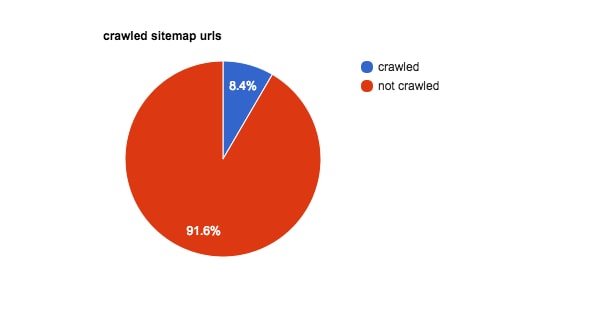
On this shopper’s case, ninety one.6 % of sitemap URLs weren’t crawled.
Once we appeared intently on the pages not crawled, we discovered that the majority of them had precisely the identical content material and template. The one distinction was the identify of the product. It appeared Googlebot has crawled them because of the pages having similar content material. Along with this, we confirmed that Googlebot was losing time on bot traps.
I’ve handle bot traps, or infinite crawl areas, beforehand. They typically seem in web sites with in depth databases — corresponding to most ecommerce platforms — and causes search-engine robots to proceed fetching pages in an countless loop. An instance of that is faceted or guided navigation, which may produce a close to limitless variety of choices. Infinite crawl areas waste Googlebot’s crawl price range, and will forestall indexing of essential pages.
The answer on this case was a painful strategy of writing distinctive content material for every web page, beginning with the perfect promoting merchandise. (Measuring the funding in distinctive content material will help decide if it is sensible to do that.)
The second instance comes from a big website within the auto business. We migrated the location to HTTPS and confronted many re-indexation delays that harm the location’s natural search rankings.
This case was notably difficult as a result of we suspected that the location had critical bot traps, however we needed to course of terabytes of log knowledge from a number of net servers, classify pages by web page sort, and emulate the performance of Search Console > Crawl > URL Parameters to know the issue.
The breakdown by web page sort allowed us to slender down the bot lure concern to the “Yr-Make-Mannequin-Class” URL group. Subsequent, we needed to see if an uncommon variety of pages crawled — because of the URL parameters — could lead on us to the bot lure.
Our log evaluation helped us determine the issue. We discovered three new URL parameters that didn’t seem within the Search Console > Crawl > URL Parameters listing, however they have been getting extra visits than anticipated. (Categorizing URL parameters helps Google keep away from crawling duplicate URLs.) The very fact they weren’t listed in Search Console > Crawl > URL Parameters prevented us from fixing the issue. I assumed Google would listing any parameters we would have liked to be fearful about, however this was fallacious. We had near one hundred drawback URL parameters.
We discovered three new URL parameters that didn’t seem within the Search Console > Crawl > URL Parameters listing, however they have been getting extra visits than anticipated.
The final instance includes a well-liked net writer. Our problem right here was that we knew there have been duplicate pages on the location, however once we ran ScreamingFrog, a spider device, we couldn’t discover them as a result of they weren’t linked internally. Nevertheless, once we searched in Google, we might see a couple of within the search outcomes — confirming that they have been listed. Guessing URLs to examine shouldn’t be notably scalable. Net logs to the rescue!
We downloaded log knowledge from the top of February to shut to the top of March and targeted on getting the reply to the query: Which URLs has Googlebot crawled that aren’t included within the XML sitemap?
Whenever you do any such evaluation, if the location is a weblog, you possibly can anticipate to see listings of articles in a class and pages with redundant URL parameters as a result of these pages are usually not included in XML sitemaps. I usually advocate together with itemizing pages — akin to listings of articles in a class — in separate XML sitemaps (even when you assign canonical tags to them), as a result of it helps to verify if they’re getting listed.
Utilizing server logs, we have been stunned to seek out quite a few ineffective pages with the identical web page titles as different official pages on the location, however no distinctive content material. We didn’t know these pages existed, however Googlebot was capable of finding them and, sadly, index lots of them. Thus the location requires some critical cleanup work to take away the ineffective pages.
As an apart, Googlebot can discover net pages that spider instruments, reminiscent of ScreamingFrog, can’t — for the next causes.
- Google makes use of hyperlinks from any website on the internet, not simply inner hyperlinks.
- WordPress websites, and most weblog platforms, ping search engines when new content material is created.
- Google has an extended reminiscence. If the web page was crawled prior to now, Google might re-crawl it sooner or later
- Google doesn’t affirm this, nevertheless it might uncover new pages from Chrome or Google Analytics logs.
Reworking Uncooked Log Knowledge
We write code for all shoppers’ log analyses. Here’s a simplified two-step course of to get began.
First, convert the log knowledge to a structured knowledge format, resembling CSV, utilizing a daily expression — a “regex.” Here’s a common expression that works in PHP.
^(S+) S+ S+ [([^]]+)] "[A-Z]+s([^s]+) [^"]+" d+ d+ "[^"]*" "([^"]*)"$
Common expressions is usually a difficult, particularly in case you are not an internet developer. In a nutshell, common expressions are search patterns. You could be acquainted with wildcards. An instance is utilizing the time period *.docx in your pc command line to listing all Microsoft Phrase paperwork in a listing. Common expressions permit for comparable, however extra refined, searches.
Use Common Expressions a hundred and one to validate and perceive how the regex above works. Enter the common expression above into the software. You’ll additionally have to enter a check string. For this instance, I’ll use the Apache log instance that was underlined, earlier within the article.
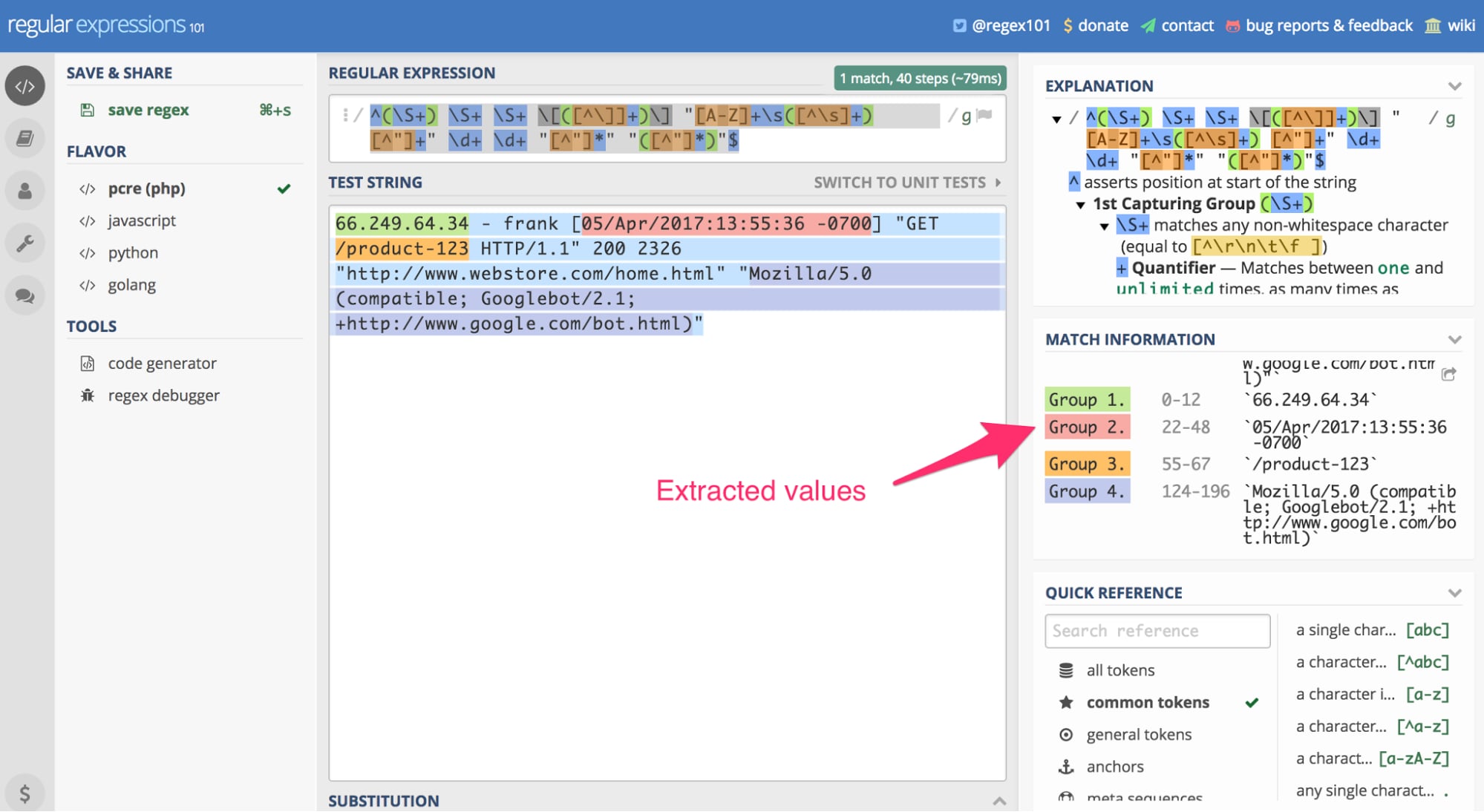
Utilizing RegEx one hundred and one, we will paste the server log entry referenced earlier within the article as a “check string” and apply the above common expression. The result’s our extracted knowledge. Click on picture to enlarge.
On this case, the software makes use of the regex search sample on the above-reference server log entry to extract the Googlebot IP, the date of the go to, the web page visited, and the browser consumer agent (on this case, Googlebot).
When you scroll down within the “Match Info” part on the suitable, you’ll see the extracted info. This common expression works particularly with the Apache mixed log format. In case your net server is Microsoft IIS or Nginx, as examples, this regex gained’t work.
The subsequent step is to write down a easy PHP script to learn the log information, one line at a time, and execute this regex to look and seize the info factors you want. You then’ll write them to a CSV file. You’ll find an instance-free script that does this right here. The code is six years previous, however, as I’ve stated, net server logs are old fashioned.
After you could have the log entries in CSV format, use a enterprise intelligence device — which retrieves and analyses knowledge — to learn the file and get solutions to your questions. I exploit Tableau, which is dear. However there are numerous different choices that begin with a free tier, comparable to Microsoft Energy BI.
In my subsequent article, I’ll clarify the way to use enterprise intelligence instruments to reply search engine marketing questions.


