Does your website suffer from one of these five content gaps?
In 2016, Google rolled Panda into its core algorithm. What this implies for site owners is that a website may be hit by (and recuperate from) a content material penalty at any time.
But, extra problematically, it additionally means it’s turning into inconceivable to diagnose why a website has dropped in rankings. Google finally doesn’t need us to know how its rating algorithm works, as a result of there’ll all the time be individuals who manipulate it. We now suspect that core alerts are rolled out so slowly that SEOs gained’t even realise when Penguin or Panda has refreshed.
For this cause, it makes it essential that we perceive how nicely our website is performing always. This weblog submit is meant to point out you methods to do a complete content material audit at scale, to be able to discover any gaps which can result in rankings penalties.
Essentially, there are 5 kinds of content material gaps an internet site might endure from. I’ll clarify every one, and present you ways yow will discover each occasion of it occurring in your web site FAST.
B. Internally duplicated content material
Internally duplicated content material is the daddy of content material gaps. Duplicating optimised content material throughout a number of pages will trigger cannibalisation points, whereby Google won’t know which inner web page to rank for the time period. The pages will compete for rating alerts with one another, decreasing the rankings in consequence.
Further to this, when you have sufficient duplicate content material inside a listing in your website, Google will deal with that whole listing as low high quality and penalise the rankings. Should the content material be hosted on the basis, your website’s complete rankings are beneath menace.
To discover these at scale you need to use Screaming Frog’s customized extraction configuration to tug all of your content material out of your website, then examine in Excel for duplicates. Using this technique, I was capable of finding S,000 duplicate pages on a website inside a number of hours.
To configure Screaming Frog you first want to repeat the CSS selector on your content material blocks on all of your pages. This must be comparatively easy ought to your pages comply with a constant template.
Go onto the web page, proper click on on the content material and go to examine aspect. This will open up the correct panel on the actual attribute which you proper clicked on. From there, proper click on once more, however on the attribute, go to copy, then choose copy selector:
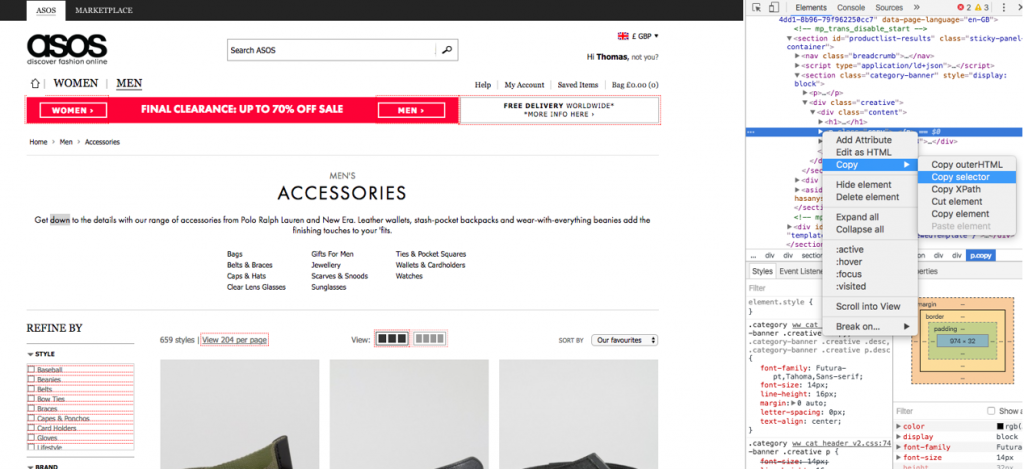
From right here you should go into Screaming Frog. Go into the configuration drop down and choose customized, then extraction.
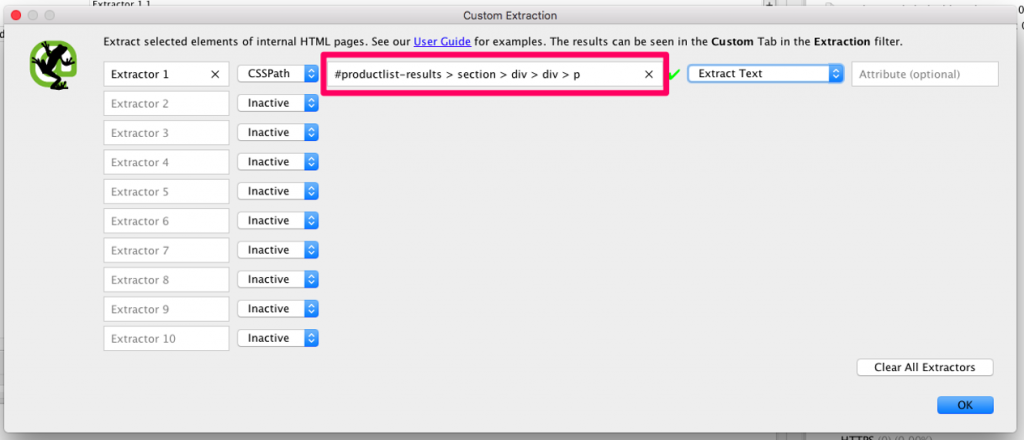
From right here this can deliver up the under field, which you’ll then want to pick CSSPath because the mode, after which paste your selector into the highlighted area, and alter the second drop right down to extract textual content.
Now if I run a crawl on the ASOS web site, Screaming Frog goes to extract the above the fold content material from all of the class pages.
You can specify as much as 10 separate paths to extract, so when you have got templates with a number of content material blocks, for instance above and under the merchandise, or class and product & static web page templates, you’ll need to specify them in the identical approach I have simply proven.
Now, it will be most unlikely that a whole web page’s content material, or a whole block of content material, shall be duplicated. Usually spun content material retains nearly all of the content material the identical however will substitute particular key phrases. So looking for duplicate content material based mostly on whole blocks of content material is fairly futile. Luckily I have created a duplicate content material software for this actual state of affairs.
Fire up the software and enter simply the URL and content material into the required columns on the enter tab. Essentially what we now have to do is cut up the content material down into sentences and examine occurrences this manner.
The output will solely work when you’ve got a single content material column, so when you’ve got needed to extract a number of content material blocks on every URL merely mix them earlier than you paste into the device. You can do that with the concatenate perform which for instance would seem like this (ought to your content material be in columns A2 & B2).
=concatenate(A2, “.”, “B2”)
The interval within the center is important (in case your content material doesn’t include durations on the finish) as a result of we’re going to cut up the content material out by textual content to columns by full sentences, so will use the interval because the delimiter.
Next spotlight the column with the content material in it, then choose textual content to columns. Select delimited, then choose different and specify a interval because the delimiter.

Once you could have achieved this you will want to amend the formulation in column A3 relying on what number of columns of delimited textual content you will have.

In my instance I have ten columns so I will edit the method to show as this:
=A2+10
Drag the formulation down so we’re including ten onto the determine of the previous cell. This step is important because it permits us to group our delimited content material by URL on the Output sheet.
From right here your Output sheet will auto populate. If you’ve obtained over one hundred,000 rows of knowledge, you will want to tug the formulation down till you get errors.
From right here I would lock down the formulation by pasting as particular to hurry up the spreadsheet. Then clear up the Output sheet by eradicating all errors and 0s.
Finally go into the pivot desk spreadsheet and refresh the desk to point out all URLs sorted by highest quantity of duplicate occurrences. You can broaden the URL to see precisely which sentences are being duplicated.

In this instance I discovered a ton of pages (S,927 pages) which had closely duplicated one another inside a few hours complete.
P. Externally Duplicated Content
Externally duplicated content material is content material which has both been purposefully syndicated on a number of web sites, or scraped by malicious net robots. A prime instance of externally duplicated content material is corporations copying producers descriptions as an alternative of writing one thing distinctive.
When a search engine discovers content material which has been duplicated throughout a number of web sites, it is going to typically work out the originator of the content material after which throw the remaining out of its index. Normally it’s fairly good at this, but when our web site has points will crawl finances, or will get its content material syndicated by an internet site with far larger authority, there’s a probability that Google will present them over us.
Finding externally duplicated content material begins a lot in the identical was as earlier than. Extract your content material from the web site and use the obtain to separate the info out into particular person sentences.
Next, we simply want to dam quote a number of the knowledge and search it into Google (use concatenate to shortly put all of your knowledge into block quotes). To automate this course of, we now have our personal software which may do that for hundreds of searches at a time. A good free various can be to make use of URL profiler’s easy SERP scraper.
What you’re primarily doing right here is performing a seek for a block of your content material in Google. If your website doesn’t present up in K.M for this, then you’ve got an enormous drawback.
Search Engine Watch is closely scraped. Here I have accomplished a seek for a little bit of a earlier weblog submit of mine, and Google have discovered 272 outcomes!

Search Engine Watch continues to be in first place, which isn’t a problem, however do you have to discover situations the place you’re outranked, you’re going to should rewrite that content material.
If you’d wish to entry the duplicate content material calendar right away merely click on on the button under:
A. Content Gaps Across Devices
The impending cellular first algorithm means this situation must be on the forefront of everybody’s minds. Google have publicly said that desktop web sites can be judged on the content material which is displayed on their cellular website first. This means if we now have cellular pages with out content material the place it seems on desktop, we’re going to take successful to our rankings.
To discover content material gaps it’s the identical course of as earlier than. You ought to have already got crawled all your pages from a desktop viewpoint. Now you simply have to undergo all of the templates once more, however in cellular view.
Fire up the webpage and go into examine component and alter gadget to cellular:
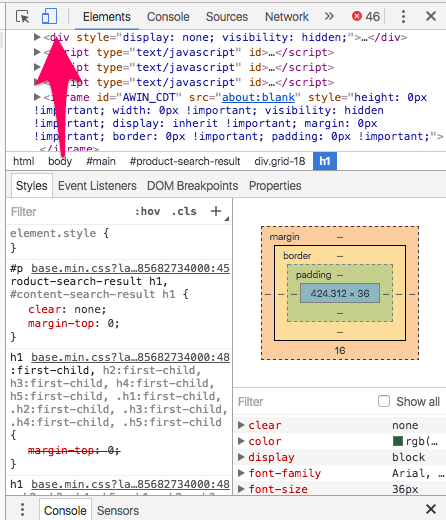
Go into the physique of content material and replica the selectors in the identical means as earlier than and run a crawl on all of your URLs once more.
Once you’re completed you possibly can examine content material aspect by aspect in Excel for gaps. Remember to concatenate your knowledge ought to you’ve a number of selectors per web page.
Put them in an Excel doc and a easy perform will make it easier to spot gaps immediately.

Here all I did was the next perform and I’ve obtained some outcomes immediately:
=IF(B2=C2, “Match”, “No Match”)
The consensus now appears to be that accordions are okay on cellular, so don’t fear about compromising your design to get all of your content material in. Just ensure it’s all there on the web page.
A. Thin content material
Thin content material is simply as massive a priority as duplicate content material for the apparent causes. Without a big quantity of helpful content material on a web page Google will be unable to know the subject of the web page and so the web page will wrestle to rank for something in any respect. Furthermore, how can a webpage declare to be an authority on a subject if it doesn’t include any info on it? Google wants content material as a way to rank a web page, that is web optimization a hundred and one!
Luckily, we’re already ninety% of the best way there to diagnosing all our skinny content material pages already. If you will have accomplished steps M-A you’ll have already got the content material in your cellular and desktop web site by URL.
Now we simply want to repeat on this formulation, altering the cell reference relying on what we’re analysing:
=IF(LEN(TRIM(B2))=zero,zero,LEN(TRIM(B2))-LEN(SUBSTITUTE(B2,” “,””))+B)
This will give us the phrase rely of the URL (for each cellular and desktop). Then undergo and lift any pages with lower than 300 phrases as requiring further content material.
H. Content above the fold on web page load
The ultimate sort of content material hole is an enormous bugbear of mine. It is estimated that eighty% of our consideration is captured by the part of a webpage that’s seen on web page load.
Google understands that content material buried on the backside of a web page might be by no means going to get learn. As a end result, they don’t give as a lot weighting to the content material right here. No matter how a lot beneficial content material you’ve gotten on a web page, if a big chunk of this isn’t seen on web page load then this can be a wasted effort.
In order to diagnose how a lot above the fold content material we’ve, we might want to rerun our crawls, however this time we solely need to extract the content material blocks that are seen on web page load. From right here, simply operating the above phrase rely components can be adequate to diagnose content material gaps.
There you’ve gotten it. What do you do with duplicate/skinny content material pages when you uncover them? I’d advocate each URL ought to have no less than 200-300 phrases of distinctive, helpful content material on it, with at the least 50-one hundred phrases showing above the fold. If you can’t produce that quantity of priceless info on the web page, then both the web page shouldn’t exist or the web page shouldn’t be indexable.

