Duplicate content material stays a standard impediment on the subject of growing natural search visitors on retailer web sites.
Here are a few of the benefits of addressing duplicate content material to extend web optimization efficiency, in comparison with different marketing actions like hyperlink constructing, content material marketing, or content material promotion:
- Duplicate content material consolidation might be executed comparatively shortly, because it requires a small set of technical modifications;
- You will probably see improved rankings inside weeks after the correction are in place;
- New modifications and enhancements to your website are picked up quicker by Google, because it has to crawl and index fewer pages than earlier than.
Consolidating duplicate content material isn’t about avoiding Google penalties. It is about constructing hyperlinks. Links are useful for search engine marketing efficiency, but when hyperlinks find yourself in duplicate pages they don’t make it easier to. They go to waste.
Duplicate Content Dilutes Links
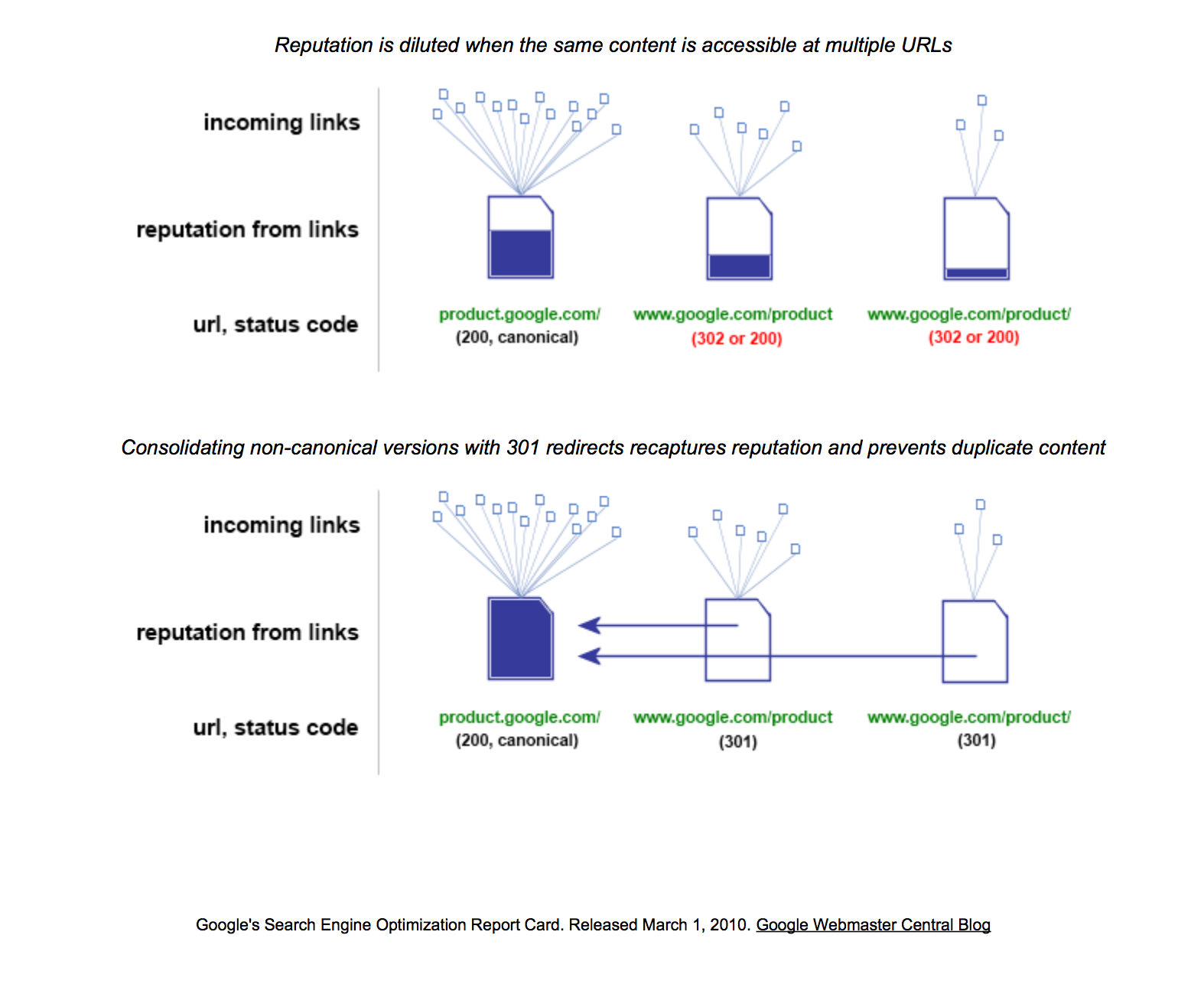
The similar content material being accessible by a number of URLs dilutes status. Source: Google.
I discovered one of the best rationalization of this years in the past when Google revealed an web optimization audit (PDF) that it carried out by itself websites.
The prime portion of the illustration above has three pages of the identical product. Each one among them accumulates hyperlinks and corresponding web page fame. Google and different main search engines nonetheless contemplate the standard and amount of hyperlinks from third celebration websites as a type of endorsement. They use these hyperlinks to prioritize how deep and sometimes they go to website pages, what number of they index, what number of they rank, and the way excessive they rank.
The fame of the primary web page, also referred to as the canonical web page, is diluted as a result of the opposite two pages obtain a part of the popularity. Because they’ve the identical content material, they are going to be competing for a similar key phrases, however just one will seem in search outcomes more often than not. In different phrases, these hyperlinks to the opposite pages are wasted.
The decrease portion of the illustration exhibits that by merely consolidating the duplicates, we improve the hyperlinks to the canonical web page, and its fame. We reclaimed them.
The outcomes may be dramatic. I’ve seen a forty five % improve in income yr over yr — over $200,000 in lower than two months — from eradicating duplicate content material. The additional income is coming from many extra product pages that beforehand didn’t rank and didn’t obtain search-engine visitors because of duplicate content material.
How to Detect Duplicate Content
To decide in case your website has duplicate content material, sort in Google website:yoursitename.com, and verify what number of pages are listed.
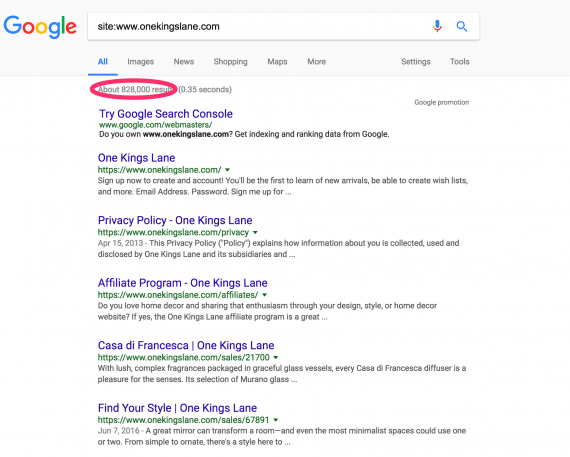
Type, in Google, “website:yoursitename.com”, and examine what number of pages are listed.
Products ought to make up the majority of the pages on most retailer websites. If Google lists much more pages than you’ve got merchandise, your website probably has duplicate content material.
If your XML sitemaps are complete, you need to use Google Search Console and examine the variety of pages listed in your XML sitemaps versus the variety of complete listed pages in Index Status.
Duplicate Content Example
One Kings Lane is a retailer of furnishings and housewares. Using a diagnostic software, I can see that Onekingslane.com has over 800,000 pages listed by Google. But it seems to have a replica content material drawback.
In navigating the location, I discovered a product web page — a blue rug — that has no canonical tag to consolidate duplicate content material. When I searched in Google for the product identify — “Fleurs Rug, Blue” — it appeared to rank primary.
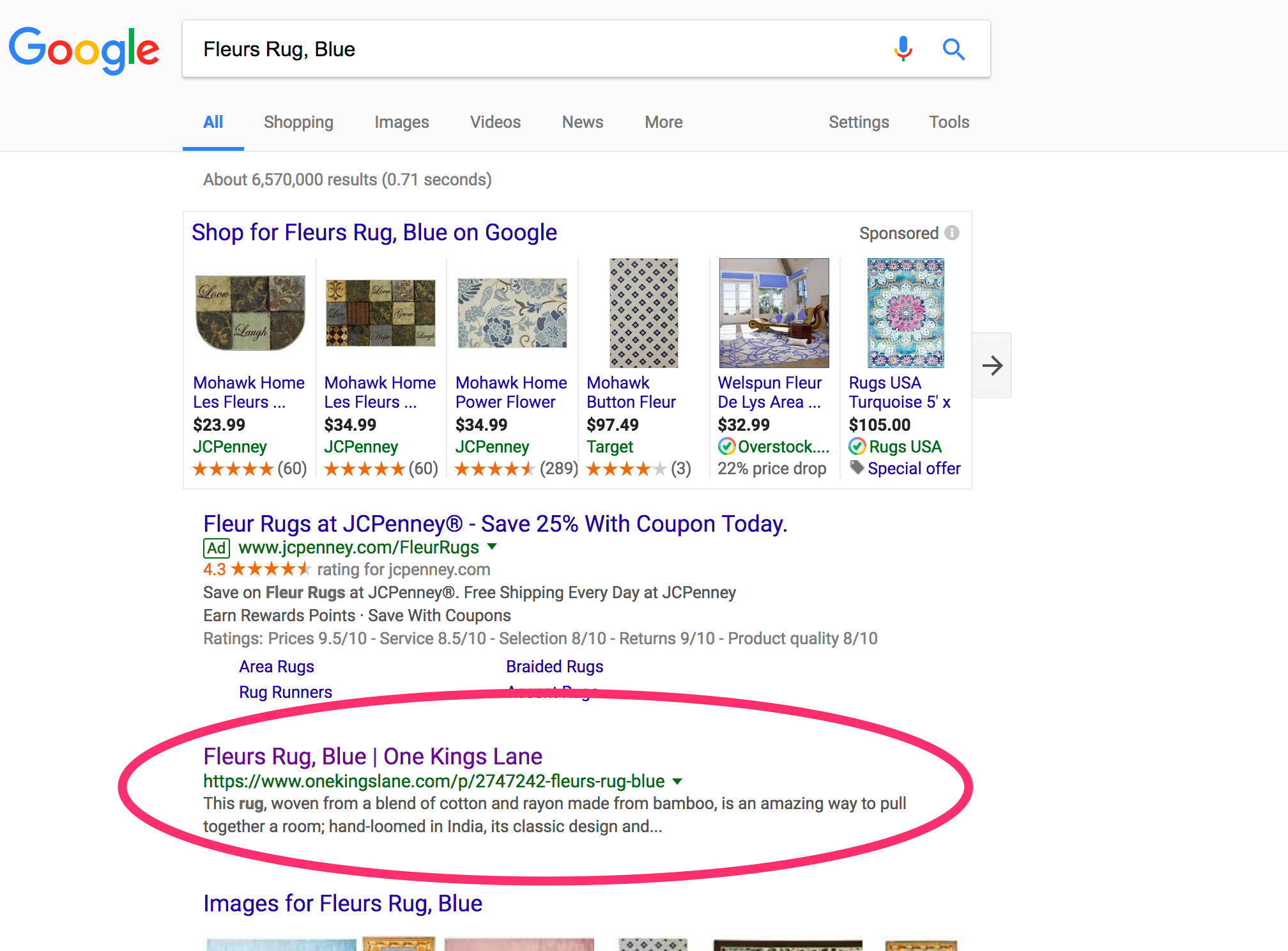
One Kings Lane has a prime rank on Google for “Fleurs Rug, Blue” regardless of not having canonical tags.
But, when I clicked on that search itemizing, I went to a special web page. The product IDs are totally different: 4577674 versus 2747242. I get one web page whereas navigating the location, one other listed, and neither has canonical tags.
This is probably going inflicting a fame dilution, regardless that the web page ranks primary for the search “Fleurs Rug, Blue.” But most product pages rank for lots of of key phrases, not simply the product identify. In this case, the dilution is probably going inflicting the web page to rank for much fewer phrases that it in any other case might.
However, duplicate content material isn’t the most important problem on this instance. When I clicked on that search end result, I went to a nonexistent web page.
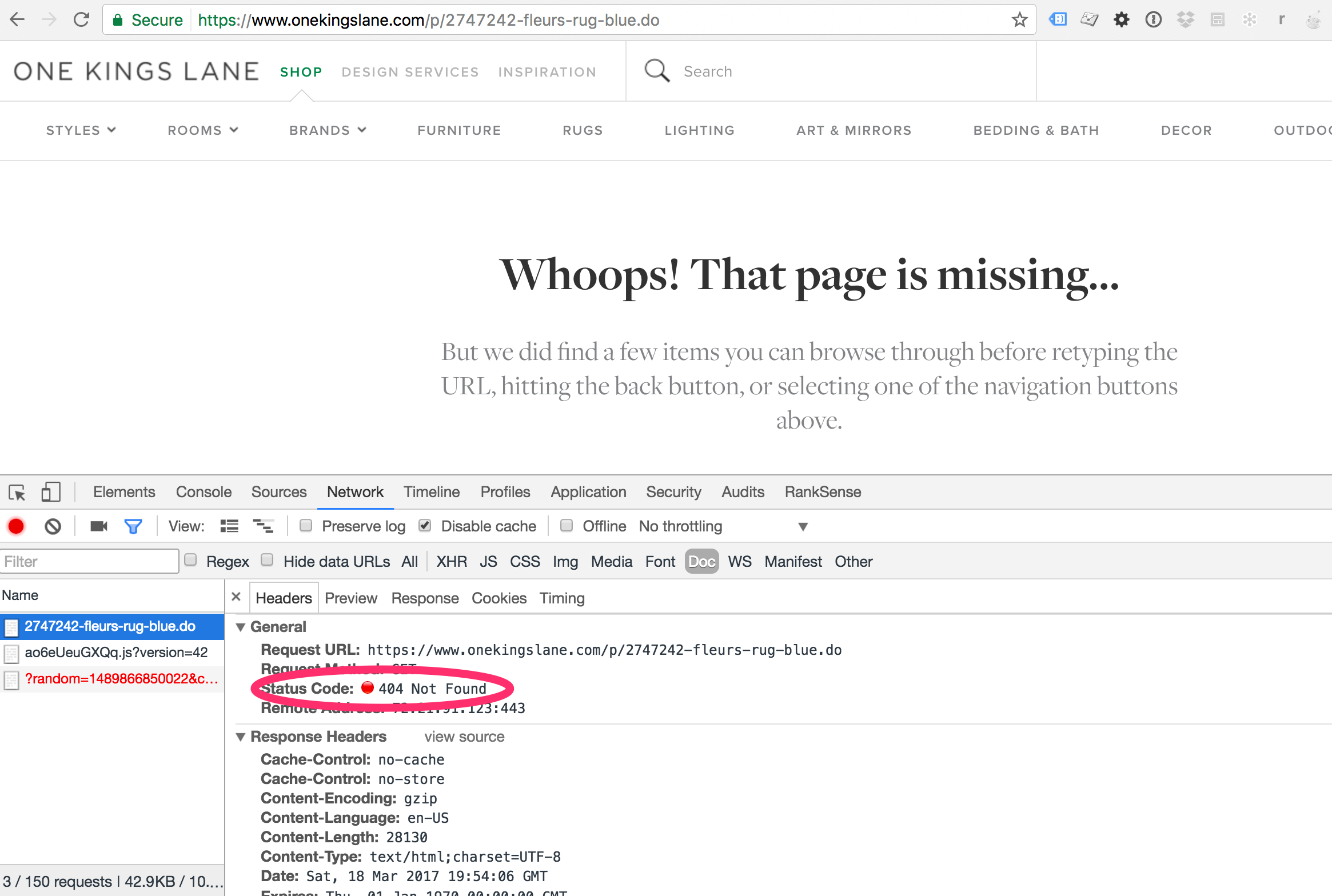
Clicking the search end result for the blue rug produced an error web page.
The web page not exists. Google will doubtless this product from the search outcomes.
Even if One Kings Lane rebuilds the product web page, giving it a brand new product ID, it might take weeks for Google to select it up, as Googlebot has to crawl at the very least 800,000 pages on the complete website.
Correcting Duplicate Content
An outdated tactic to deal with duplicate content material is to dam search engines from crawling the duplicate pages within the robots.txt file. But this doesn’t consolidate the fame of the duplicates into the canonical pages. It avoids penalties, however it doesn’t reclaim hyperlinks. When you block duplicate pages by way of robots.txt, these duplicate pages nonetheless accumulate hyperlinks, and web page fame, which doesn’t assist the location.
Instead, what follows are recipes to deal with the most typical duplicate content material issues utilizing 301 redirects in Apache. But first, it’s useful to know the use instances for everlasting redirects and canonical tags.
Canonical tags and redirects each consolidate duplicate pages. But, redirects are usually simpler as a result of search engines not often ignore them, and the pages redirected don’t have to be listed. However, you possibly can’t (or shouldn’t) use redirects to consolidate close to duplicates, reminiscent of the identical product in several colours, or merchandise listed in a number of classes.
The greatest duplicate content material consolidation is the one that you simply don’t need to do. For instance, as an alternative of making a website hierarchy with website.com/category1/product1, merely use website.com/product1. It eliminates the necessity to consolidate merchandise listed in a number of classes.
Common URL Redirects
What follows are Apache redirect recipes to deal with 5 widespread duplicate content material issues.
I will use mod_rewrite, and assume it’s enabled in your website
RewriteEngine On # This will allow the Rewrite capabilities
I may also use htaccess checker to validate my rewrite guidelines.
Protocol duplication. We need to be sure we solely have our retailer accessible by way of HTTP or HTTPS, however not each. (I addressed the method of shifting an internet retailer to HTTPS, in “search engine marketing: How to Migrate an Ecommerce Site to HTTPS.”) Here I will pressure HTTPS.
RewriteEngine On # This will allow the Rewrite capabilities RewriteCond %HTTPS !=on # This checks to ensure the connection just isn't already HTTPS RewriteRule ^/?(.*) https://www.webstore/$M [R=301,L]
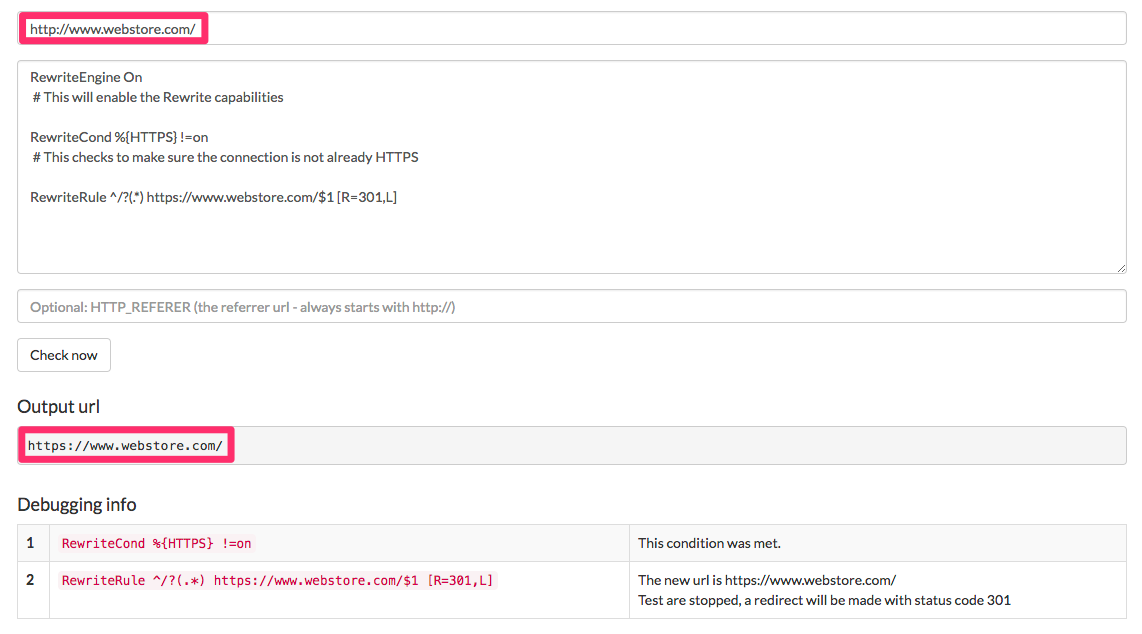
This checks to ensure the connection isn’t already HTTPS.
Note that this rule will even tackle the uncommon case of IP duplication, the place the location can also be obtainable by way of the IP handle.
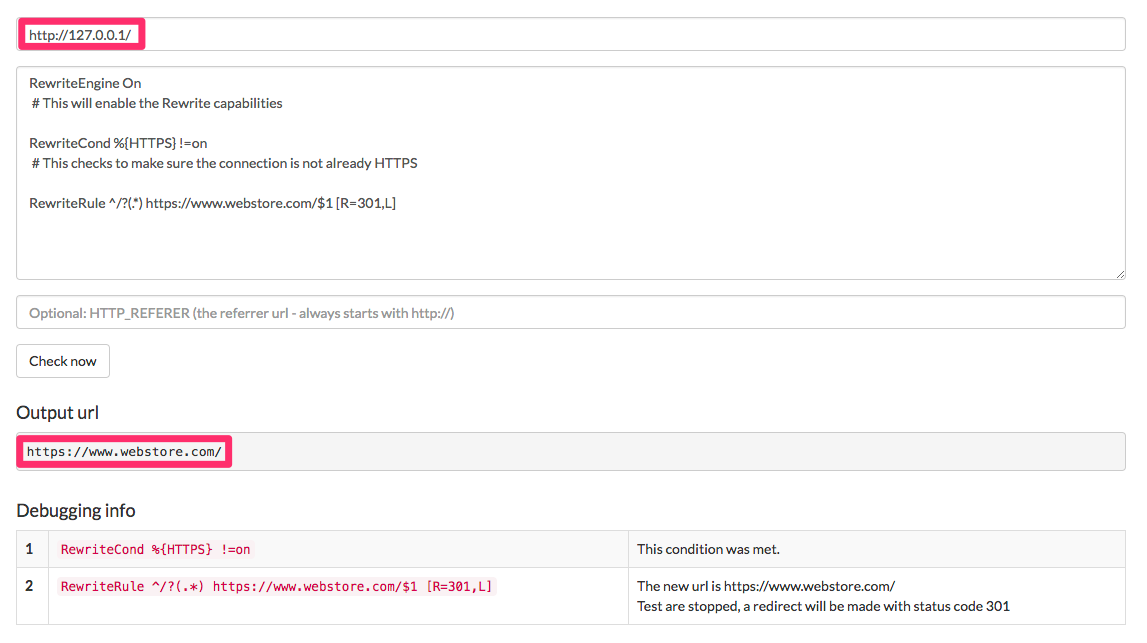
This rule may also work to deal with the uncommon case of IP duplication, the place the location can also be obtainable by way of the IP handle.
For the subsequent examples, we’re going to assume we have now the complete website utilizing HTTPS.
Trailing slash duplication. We need to ensure we solely have pages with a trailing slash or with no trailing slash, however not each. Below you’ll find examples of how one can accomplish each instances.
This rule provides lacking trailing slashes:
RewriteEngine On # This will allow the Rewrite capabilities %REQUEST_FILENAME !-f # This checks to ensure we don’t add slashes to information, i.e. /index.html/ can be incorrect RewriteRule ^([^/]+)/?$ https://www.webstore.com/$M/ [R=301,L]
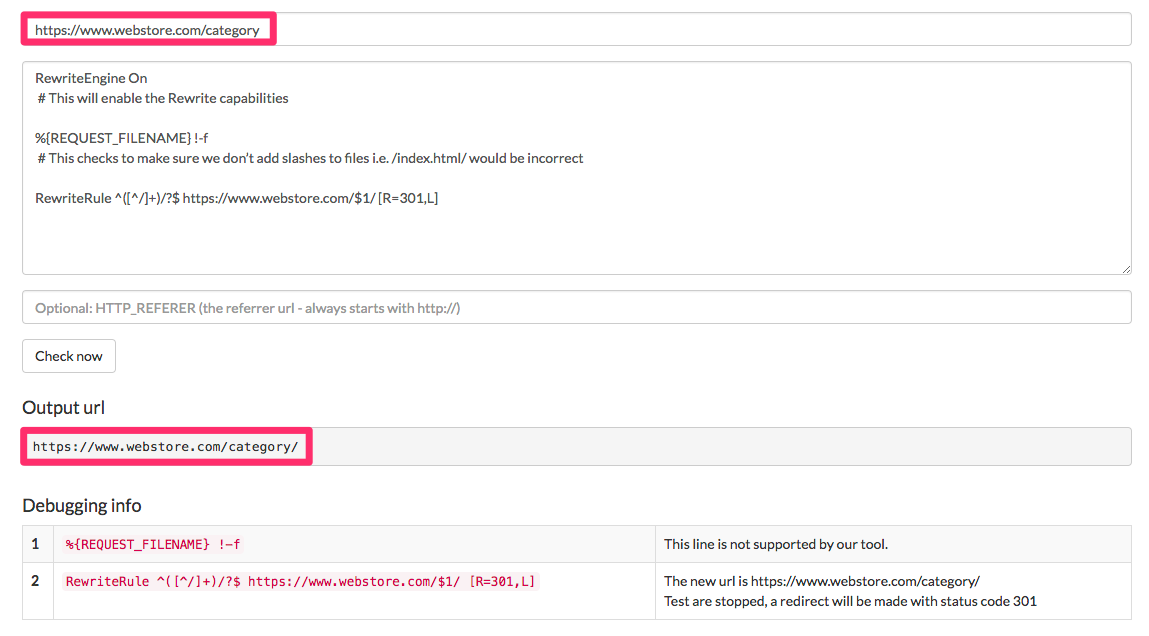
This rule provides lacking trailing slashes.
This one removes them:
RewriteEngine On # This will allow the Rewrite capabilities %REQUEST_FILENAME !-f # This checks to ensure we don’t add slashes to information, i.e. /index.html/ can be incorrect RewriteRule (.+)/$ https://www.webstore.com/$B [R=301,L]
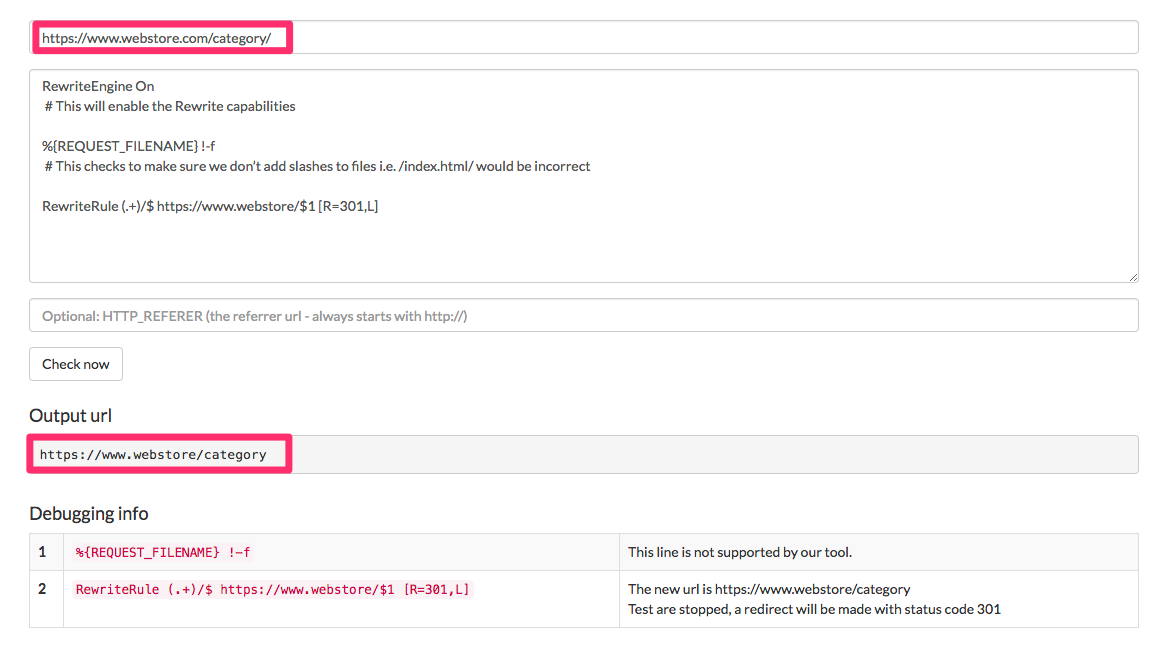
This rule removes lacking trailing slashes.
File duplication. A widespread case of a replica file is the listing index file. In PHP based mostly methods, it’s index.php. In .NET methods, it’s default.aspx. We need to take away this listing index file to keep away from the duplicates.
%REQUEST_FILENAME -f # This is elective and checks to ensure we're solely affecting information RewriteRule (.*)/?index.php$ https://www.webstore.com/$B [R=301,L]
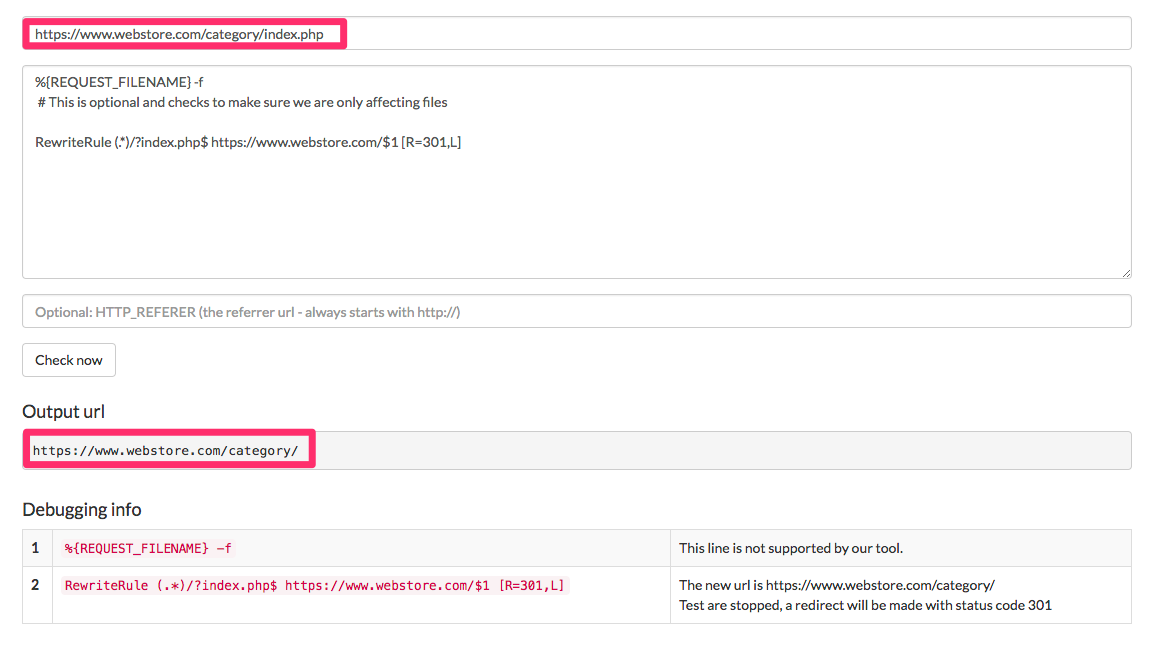
This rule removes this listing index file.
Legacy pages duplication. Another widespread state of affairs is ecommerce methods that add search-engine-pleasant URLs, whereas leaving the equal non-search-engine-pleasant URLs accessible with out redirects.
RewriteCond %QUERY_STRING ^id=([0-9]+) #this makes positive we solely do it when there are ids within the URL question strings RewriteRule ^class/product.php /product-%B.html? [R=301,L] #Note that common expression matches from a RewriteCond are referenced utilizing % however these in a RewriteRule are referenced utilizing $
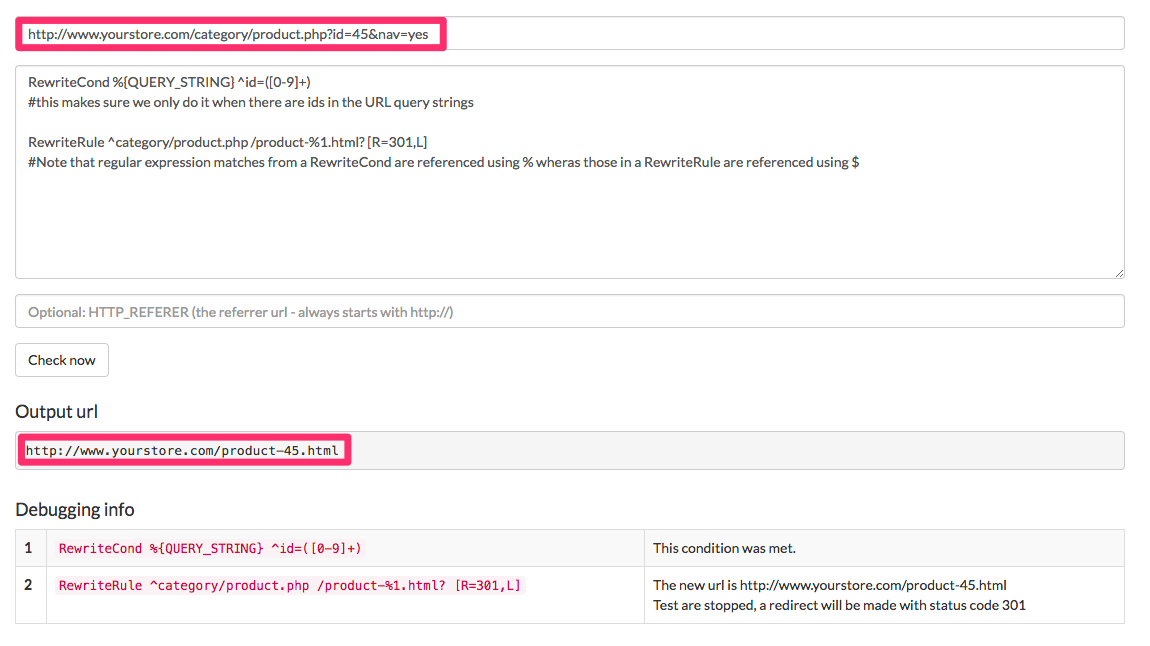
This rule stops non-search engine pleasant URLs from being accessible with out redirects.
One-to-one Redirects
In the examples above, I am assuming that the product IDs are the identical for each URLs — the canonical model and the duplicate. This makes it attainable to make use of a single rule to map all product pages. However, the product IDs are oftentimes not the identical or the brand new URLs don’t use IDs. In such instances, you will want one-to-one mappings.
But large one-to-one mappings and redirects will drastically decelerate a website — as a lot as 10 occasions slower in my expertise.
To overcome this, I use an software referred to as RewriteMap. The particular MapType to make use of on this case is the DBM sort, which is a hash file, which permits for very quick entry.
When a MapType of DBM is used, the MapSource is a file system path to a DBM database file containing key-worth pairs for use within the mapping. This works precisely the identical means because the txt map, however is far quicker, as a result of a DBM is listed, whereas a textual content file just isn’t. This permits extra speedy entry to the specified key.
The course of is to save lots of a one-to-one mapping file right into a textual content file. The format is described under Then, use the Apache device httxt2dbm to transform the textual content file to a DBM file, comparable to the next instance.
$ httxt2dbm -i productsone2one.txt -o productsone2one.map
After you create the DBM file, reference it within the rewrite guidelines. The earlier rule might be rewritten as:
RewriteMap merchandise “dbm:/and so on/apache/productsone2one.map” #this maps consists of previous URLs mapped to new URLs RewriteCond %QUERY_STRING ^id=([0-9]+) #this makes positive we solely do it when there are ids within the URL question strings RewriteRule ^(.*)$ $merchandise:$B|NOTFOUND [R=301,L] #this seems to be up any legacy URL within the map, and 301 redirects to the alternative URL additionally discovered within the file #if the mapping shouldn't be within the dbm file, the server will return 404
Basically, reference the map and identify it merchandise. Then use the map within the rewrite rule. In this case, if there isn’t a match for a legacy product URL, I’m returning a 404 error so I can discover these pages in Google Search Console and add them to the map. If we returned the identical web page, it might create a redirect loop. There are extra difficult options that may handle this, however are outdoors the scope of this text.



